
In July 2016, Workday acquired Platfora, a leading big data analytics company that offered an end-to-end self-service data discovery platform. Since then, the same team has been working diligently with Platfora’s technology to develop Workday Prism Analytics. With this new analytics product, users can bring external data sources into Workday, govern them along with existing Workday data sources, and generate financial and HR insights that can be shared across their organizations. The product was launched at Workday Rising in September 2017, providing businesses with powerful, self-service tools to make data-driven decisions.
Workday Prism Analytics is a native component in the Workday fabric, echoing the Power of One. This means that, on the surface, the product has the same look and feel as other Workday applications. Under the hood, it works seamlessly and securely with both Workday and non-Workday data. These requirements pose many interesting challenges, but also give us an opportunity to innovate upon our previous designs.
Operating from within the ecosystem, Workday Prism Analytics takes data pipelines from raw data to visualization. This blog post focuses on how we deal with the first part of this process — data preparation.
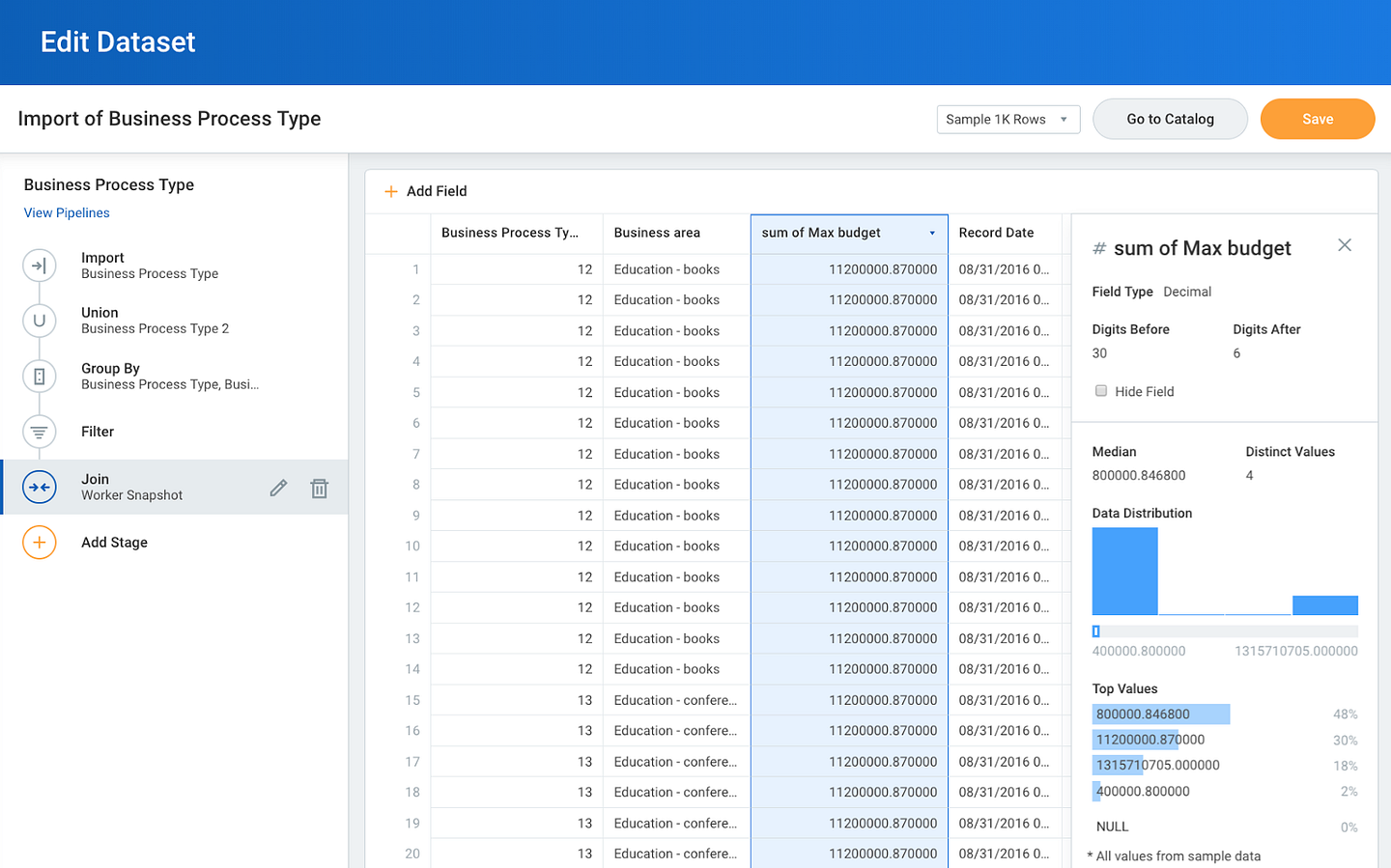 Workday Prism Analytics operates natively in Workday, and models its UI and UX after existing Workday products.
Workday Prism Analytics operates natively in Workday, and models its UI and UX after existing Workday products.
Interactive Data Preparation
Data preparation involves importing, cleaning, transforming, and aggregating raw data to be ultimately queried for insights. It is similar to Extract, Transform, Load (ETL), but designed for non-technical users rather than IT professionals. As a backend engineer on the data preparation team, my work enables Workday customers to build and iterate on their data pipelines.
An essential feature in modern data preparation is self-service, and along with it, interactivity. When building a data pipeline, users want to quickly make edits and receive feedback. Workday Prism Analytics embraces this idea by allowing data pipelines to be executed on a data sample. Users can immediately have a sense of what the pipeline results look like, and make changes until they are ready to apply them to the full data.
To benefit from decades of innovations in data processing, we use Apache Spark as the engine for data preparation. Also, as a distributed data processing system that can be modified for both interactive and batch workloads, Spark is a good middle ground for our hybrid use case. In fact, we started working with Spark in the Platfora product, and became more tightly integrated with it over time.
Another feature of modern data preparation is usability. Traditional ETL tools often expose a SQL interface or builder, requiring database admins to write and maintain complex queries. In contrast, Workday Prism Analytics aims to have a clean and intuitive UI that hides the complexity of SQL, and is configured with suitable system defaults tailored for Workday-style workloads.
Bringing Data into the System
What are Workday-style workloads? As mentioned previously, Workday Prism Analytics is designed to bring together data from different sources. This means that, first and foremost, it has to be capable of parsing various file formats. These formats include plain text formats such as CSV, compressed formats such as Parquet, and Workday’s internal file formats. Each format has its own parsing options that we need to make configurable. The inputs also could contain malformed data, which should be taken into account by the system when performing calculations.
One common use case in analytics involves incremental updates, where data is periodically fetched to produce updated reports. To facilitate this, we need to handle schema evolution, and know what to do when new columns are added, when previous columns are removed, or when existing columns change names or data types.
A modern data preparation solution requires a rich data model containing extensive support for data types. Aside from primitive types (eg. INTEGER, STRING, DECIMAL) and structured types (eg. ARRAY, MAP, STRUCT), we must also understand Workday data types. One example of a Workday data type is the INSTANCE type, which represents the ID of a Workday object. INSTANCE is crucial in connecting Workday products and functionalities, and Workday Prism Analytics, as a part of the ecosystem, has to provide the same features.
Preparing Data within Workday Prism Analytics
Once data is inside Workday, our analytics product allows for a large library of row and aggregate functions to manipulate data, and also exposes data transformation operations as UI-based “transformation stages”. These operations include, but are not limited to, SQL operators such as JOIN, GROUP BY, and UNION. Transformation stages are linked together to form pipelines, allowing users to interactively navigate and visualize their changes.
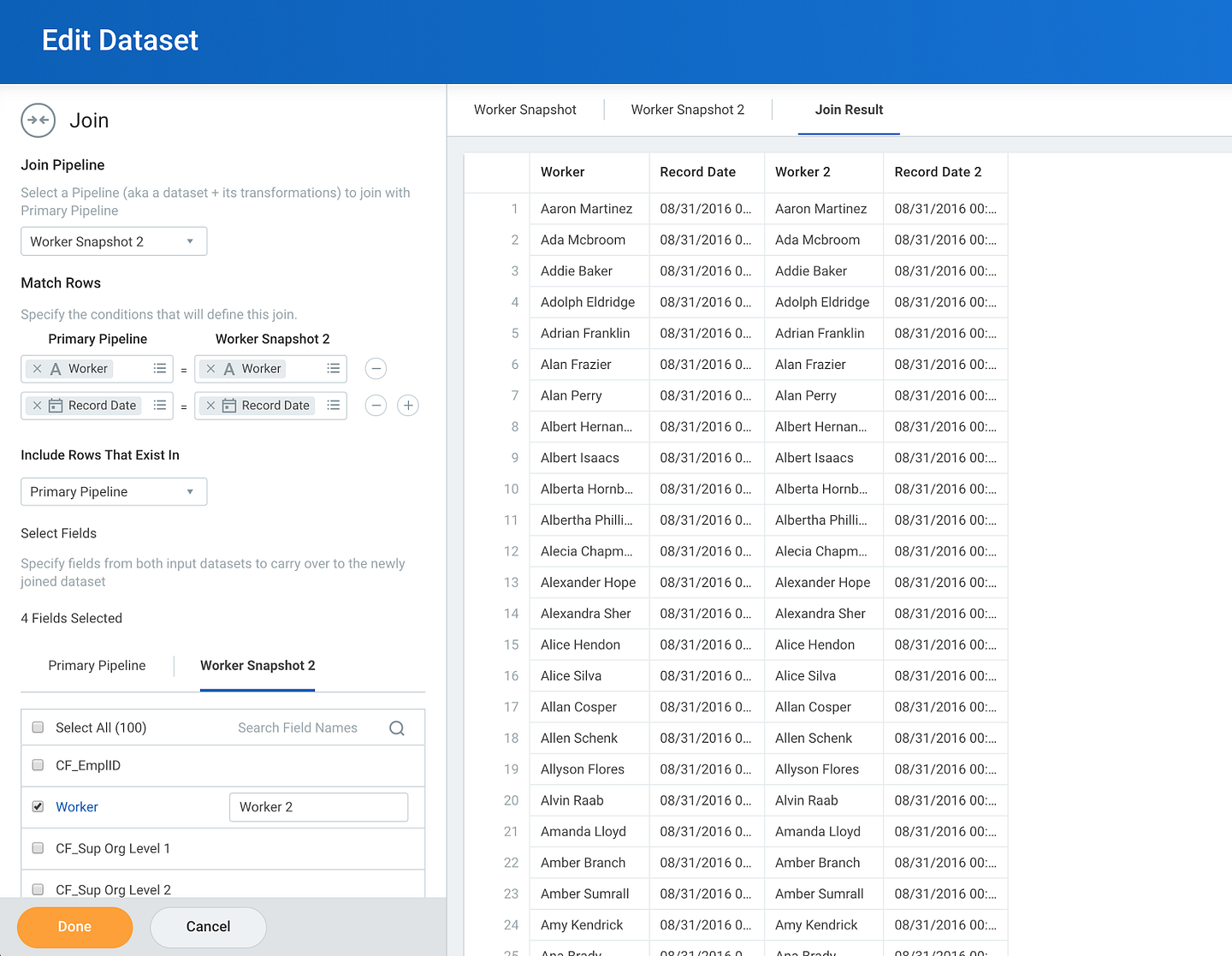 Workday Prism Analytics exposes data transform capabilities such as JOIN in a user-friendly UI.
Workday Prism Analytics exposes data transform capabilities such as JOIN in a user-friendly UI.
Implementing a seamless UX experience for transformations requires thoughtful design and innovation. For example, when an user creates a JOIN transformation, what should be the default output columns? It might make sense to use all columns from both sides, but if there are hundreds of columns, we risk putting unnecessary load on Workday while producing results that users might not want.
Additionally, the joined pipelines can have duplicate column names. Clearly, it would be ambiguous to include both names as-is in the output. Dropping one of them is not a good idea either, because the names can have different meanings. Therefore the system should choose a way to automatically generate unique names, which has its own collection of options and tradeoffs.
However, the biggest problem in building pipelines is arguably seeing sample results. This can be especially difficult when there are many joins in the pipeline, because join keys may not be present in the sampled data. To show better sampled results, we have to explore algorithms like reservoir sampling that selectively pick the relevant rows.
Get practical knowledge of workday analytics at Workday HCM Online Training
Product Considerations
Data preparation features aside, performance is also crucial. Not only do we have to return sample results quickly, we must scale to large amounts of data in data pipelines. Moreover, our output is consumed by downstream components, including our interactive query engine for reports and visualizations. To allow for faster consumption, we materialize results in a custom file format called “lens” that is efficient for querying.
Above everything, security is paramount. Workday takes data security very seriously, with one security model across the platform. Workday Prism Analytics uses the same strict security settings we have built into all Workday products, implementing features such as encryption at rest, obfuscation of customer data in logs, and row- and column-level security that merit their own blog entries.
It is an exciting time to be a part of the Workday Prism Analytics team. Self-service analytics is becoming increasingly necessary, and we are at the forefront of making it easy for even non-technical users to learn from data.
Get practical knowledge on Workday at Workday Online Training
Workday Prism Analytics is a native component in the Workday fabric, echoing the Power of One. This means that, on the surface, the product has the same look and feel as other Workday applications. Under the hood, it works seamlessly and securely with both Workday and non-Workday data. These requirements pose many interesting challenges, but also give us an opportunity to innovate upon our previous designs.
Operating from within the ecosystem, Workday Prism Analytics takes data pipelines from raw data to visualization. This blog post focuses on how we deal with the first part of this process — data preparation.
Interactive Data Preparation
Data preparation involves importing, cleaning, transforming, and aggregating raw data to be ultimately queried for insights. It is similar to Extract, Transform, Load (ETL), but designed for non-technical users rather than IT professionals. As a backend engineer on the data preparation team, my work enables Workday customers to build and iterate on their data pipelines.
An essential feature in modern data preparation is self-service, and along with it, interactivity. When building a data pipeline, users want to quickly make edits and receive feedback. Workday Prism Analytics embraces this idea by allowing data pipelines to be executed on a data sample. Users can immediately have a sense of what the pipeline results look like, and make changes until they are ready to apply them to the full data.
To benefit from decades of innovations in data processing, we use Apache Spark as the engine for data preparation. Also, as a distributed data processing system that can be modified for both interactive and batch workloads, Spark is a good middle ground for our hybrid use case. In fact, we started working with Spark in the Platfora product, and became more tightly integrated with it over time.
Another feature of modern data preparation is usability. Traditional ETL tools often expose a SQL interface or builder, requiring database admins to write and maintain complex queries. In contrast, Workday Prism Analytics aims to have a clean and intuitive UI that hides the complexity of SQL, and is configured with suitable system defaults tailored for Workday-style workloads.
Know more on Workday from real-time experts at Workday Online Training Hyderabad
Bringing Data into the System
What are Workday-style workloads? As mentioned previously, Workday Prism Analytics is designed to bring together data from different sources. This means that, first and foremost, it has to be capable of parsing various file formats. These formats include plain text formats such as CSV, compressed formats such as Parquet, and Workday’s internal file formats. Each format has its own parsing options that we need to make configurable. The inputs also could contain malformed data, which should be taken into account by the system when performing calculations.
One common use case in analytics involves incremental updates, where data is periodically fetched to produce updated reports. To facilitate this, we need to handle schema evolution, and know what to do when new columns are added, when previous columns are removed, or when existing columns change names or data types.
A modern data preparation solution requires a rich data model containing extensive support for data types. Aside from primitive types (eg. INTEGER, STRING, DECIMAL) and structured types (eg. ARRAY, MAP, STRUCT), we must also understand Workday data types. One example of a Workday data type is the INSTANCE type, which represents the ID of a Workday object. INSTANCE is crucial in connecting Workday products and functionalities, and Workday Prism Analytics, as a part of the ecosystem, has to provide the same features.
Preparing Data within Workday Prism Analytics
Once data is inside Workday, our analytics product allows for a large library of row and aggregate functions to manipulate data, and also exposes data transformation operations as UI-based “transformation stages”. These operations include, but are not limited to, SQL operators such as JOIN, GROUP BY, and UNION. Transformation stages are linked together to form pipelines, allowing users to interactively navigate and visualize their changes.
Implementing a seamless UX experience for transformations requires thoughtful design and innovation. For example, when an user creates a JOIN transformation, what should be the default output columns? It might make sense to use all columns from both sides, but if there are hundreds of columns, we risk putting unnecessary load on Workday while producing results that users might not want.
Additionally, the joined pipelines can have duplicate column names. Clearly, it would be ambiguous to include both names as-is in the output. Dropping one of them is not a good idea either, because the names can have different meanings. Therefore the system should choose a way to automatically generate unique names, which has its own collection of options and tradeoffs.
However, the biggest problem in building pipelines is arguably seeing sample results. This can be especially difficult when there are many joins in the pipeline, because join keys may not be present in the sampled data. To show better sampled results, we have to explore algorithms like reservoir sampling that selectively pick the relevant rows.
Get practical knowledge of workday analytics at Workday HCM Online Training
Product Considerations
Data preparation features aside, performance is also crucial. Not only do we have to return sample results quickly, we must scale to large amounts of data in data pipelines. Moreover, our output is consumed by downstream components, including our interactive query engine for reports and visualizations. To allow for faster consumption, we materialize results in a custom file format called “lens” that is efficient for querying.
Above everything, security is paramount. Workday takes data security very seriously, with one security model across the platform. Workday Prism Analytics uses the same strict security settings we have built into all Workday products, implementing features such as encryption at rest, obfuscation of customer data in logs, and row- and column-level security that merit their own blog entries.
It is an exciting time to be a part of the Workday Prism Analytics team. Self-service analytics is becoming increasingly necessary, and we are at the forefront of making it easy for even non-technical users to learn from data.
Get more information with live examples at Workday Training



0 comments:
Post a Comment