
As they face ever-changing business requirements, our customers need to adapt quickly and effectively. When we designed Workday’s original architecture, we considered agility a fundamental requirement. We had to ensure the architecture was flexible enough to accommodate technology changes, the growth of our customer base, and regulatory changes, all without disrupting our users. We started with a small number of services. The abstraction layers we built into the original design gave us the freedom to refactor individual services and adopt new technologies. These same abstractions helped us transition to the many loosely-coupled distributed services we have today.
At one point in Workday’s history, there were just four services: User Interface (UI), Integration, OMS, and Persistence. Although the Workday architecture today is much more complex, we still use the original diagram below to provide a high-level overview of our services.
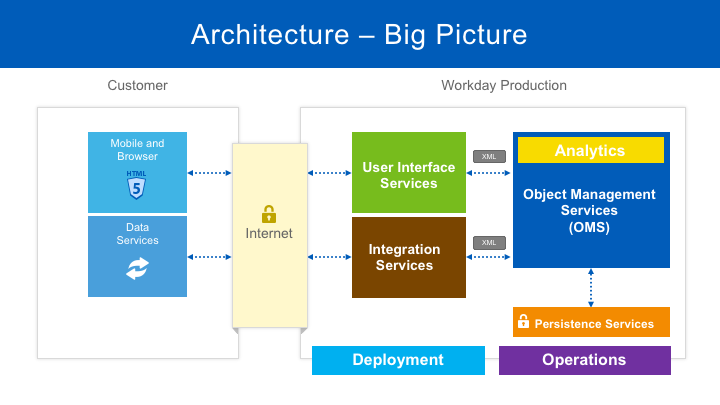
At the heart of the architecture are the Object Management Services (OMS), a cluster of services that act as an in-memory database and host the business logic for all Workday applications. The OMS cluster is implemented in Java and runs as a servlet within Apache Tomcat. The OMS also provides the runtime for XpressO — Workday’s application programming language in which most of our business logic is implemented. Reporting and analytics capabilities in Workday are provided by the Analytics service which works closely with the OMS, giving it direct access to Workday’s business objects.
The Persistence Services include a SQL database for business objects and a NoSQL database for documents. The OMS loads all business objects into memory as it starts up. Once the OMS is up and running, it doesn’t rely on the SQL database for read operations. The OMS does, of course, update the database as business objects are modified. Using just a few tables, the OMS treats the SQL database as a key-value store rather than a relational database. Although the SQL database plays a limited role at runtime, it performs an essential role in the backup and recovery of data.
The UI Services support a wide variety of mobile and browser-based clients. Workday’s UI is rendered using HTML and a library of JavaScript widgets. The UI Services are implemented in Java and Spring.
The Integration Services provide a way to synchronize the data stored within Workday with the many different systems used by our customers. These services run integrations developed by our partners and customers in a secure, isolated, and supervised environment. Many pre-built connectors are provided alongside a variety of data transformation technologies and transports for building custom integrations. The most popular technologies for custom integrations are XSLT for data transformation and SFTP for data delivery.
The Deployment tools support new customers as they migrate from their legacy systems into Workday. These tools are also used when existing customers adopt additional Workday products.
Workday’s Operations teams monitor the health and performance of these services using a variety of tools. Realtime health information is collected by Prometheus and Sensu and displayed on Wavefront dashboards as time series graphs. Event logs are collected using a Kafka message bus and stored on the Hadoop Distributed File System, commonly referred to as HDFS. Long-term performance trends can be analyzed using the data in HDFS.
As we’ve grown, Workday has scaled out its services to support larger customers, and to add new features. The original few services have evolved into multiple discrete services, each one focused on a specific task. You can get a deeper understanding of Workday’s architecture by viewing a diagram that includes these additional services. Click play on the video above to see the high-level architecture diagram gain detail as it transforms into a diagram that resembles the map of a city. (The videos in this post contain no audio.)
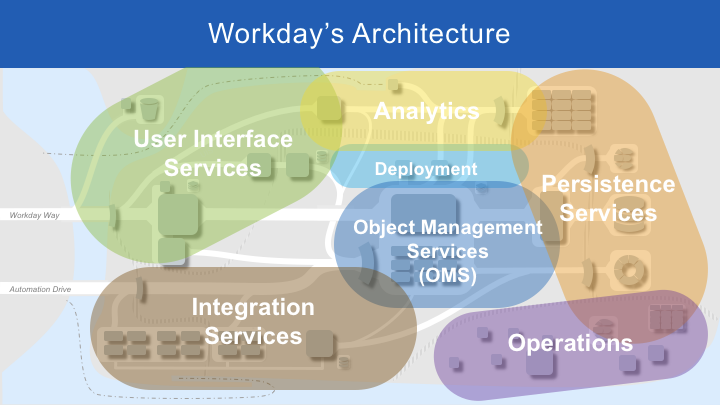
These services are connected by a variety of different pathways. A depiction of these connections resembles a city map rather than a traditional software architecture diagram. As with any other city, there are districts with distinct characteristics. We can trace the roots of each district back to the services in our original high-level architecture diagram.
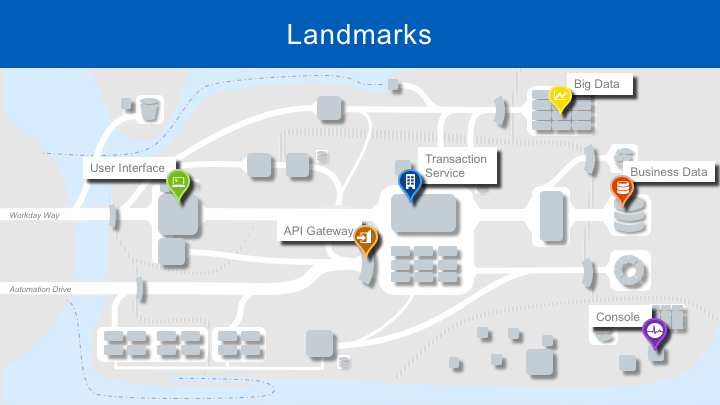
There are a number of landmark services that long-time inhabitants of Workday are familiar with. Staying with the city metaphor, users approaching through Workday Way arrive at the UI services before having their requests handled by the Transaction Services. Programmatic access to the Transaction Service is provided by the API Gateway. The familiar Business Data Store is clearly visible, alongside a relatively new landmark: the Big Data Store where customers can upload large volumes of data for analysis. The Big Data Store is based on HDFS. Workday’s Operations team monitors the health and performance of the city using the monitoring Console based on Wavefront.
User Interface Services
Zooming in on the User Interface district allows us to see the many services that support Workday’s UI.
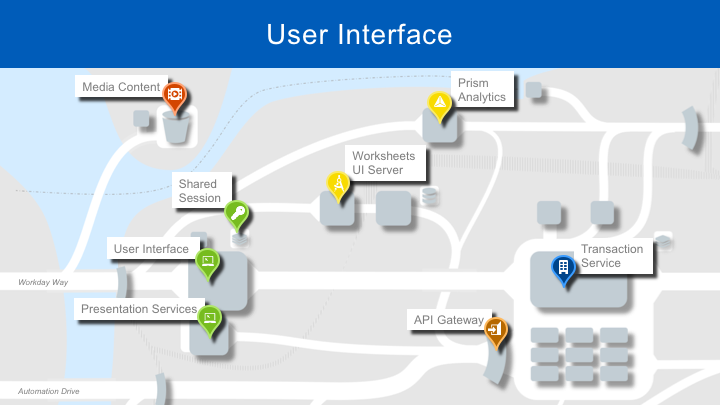
The original UI service that handles all user generated requests is still in place. Alongside it, the Presentation Services provide a way for customers and partners to extend Workday’s UI. Workday Learning was our first service to make extensive use of video content. These large media files are hosted on a content delivery network that provides efficient access for our users around the globe. Worksheets and Workday Prism Analytics also introduced new ways of interacting with the Workday UI. Clients using these features interact with those services directly. These UI services collaborate through the Shared Session service which is based on Redis. This provides a seamless experience as users move between services.
Metadata-Driven Development
This architecture also illustrates the value of using metadata-driven development to build enterprise applications.
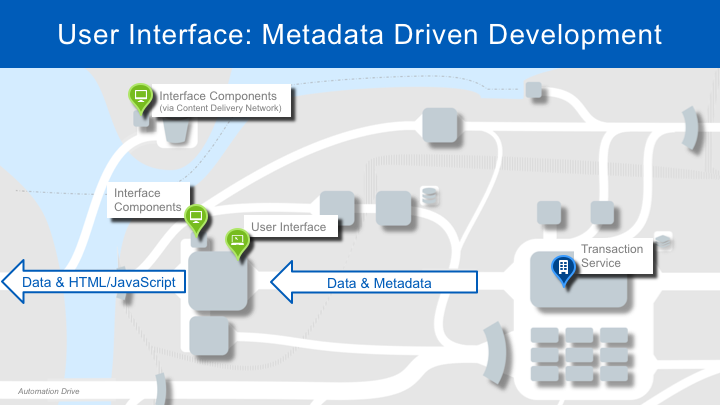
Application developers design and implement Workday’s applications using XpressO, which runs in the Transaction Service. The Transaction Service responds to requests by providing both data and metadata. The UI Services use the metadata to select the appropriate layout for the client device. JavaScript-based widgets are used to display certain types of data and provide a rich user experience. This separation of concerns isolates XpressO developers from UI considerations. It also means that our JavaScript and UI service developers can focus on building the front-end components. This approach has enabled Workday to radically change its UI over the years while delivering a consistent user experience across all our applications without having to rewrite application logic.
The Object Management Services
The Object Management Services started life as a single service which we now refer to as the Transaction Service. Over the years the OMS has expanded to become a collection of services that manage a customer’s data. A brief history lesson outlining why we introduced each service will help you to understand their purpose. Click play on the video below to see each service added to the architecture.
Originally, there was just the Transaction Service and a SQL database in which both business data and documents were stored. As the volume of documents increased, we introduced a dedicated Document Store based on NoSQL.
Larger customers brought many more users and the load on the Transaction Service increased. We introduced Reporting Services to handle read-only transactions as a way of spreading the load. These services also act as in-memory databases and load all data on startup. We introduced a Cache to support efficient access to the data for both the Transaction Service and Reporting Services. Further efficiencies were achieved by moving indexing and search functionality out of the Transaction Service and into the Cache. The Reporting Services were then enhanced to support additional tasks such as payroll calculations and tasks run on the job framework.
Search is an important aspect of user interaction with Workday. The global search box is the most prominent search feature and provides access to indexes across all customer data. Prompts also provide search capabilities to support data entry. Some prompts provide quick access across hundreds of thousands of values. Use cases such as recruiting present new challenges as a search may match a large number of candidates. In this scenario, sorting the results by relevance is just as important as finding the results.
A new search service based on Elasticsearch was introduced to scale out the service and address these new use cases. This new service replaces the Apache Lucene based search engine that was co-located with the Cache. A machine learning algorithm that we call the Query Intent Analyzer builds models based on an individual customer’s data to improve both the matching and ordering of results by relevance.
Scaling out the Object Management Services is an ongoing task as we take on more and larger customers. For example, more of the Transaction Service load is being distributed across other services. Update tasks are now supported by the Reporting Services, with the Transaction Service coordinating activity. We are currently building out a fabric based on Apache Ignite which will sit alongside the Cache. During 2018 we will move the index functionality from the Cache onto the Fabric. Eventually, the Cache will be replaced by equivalent functionality running on the Fabric.
Integration Services
Integrations are managed by Workday and deeply embedded into our architecture. Integrations access the Transaction Service and Reporting Services through the API Gateway.
Persistence
There are three main persistence solutions used within Workday. Each solution provides features specific to the kind of data it stores and the way that data is processed.
Business data is stored in a SQL database which supports tenant management operations such as backup, disaster recovery, copying of tenants, and point-in-time recovery of data.
Documents are stored in a NoSQL database, which provides a distributed document store and disaster recovery. The Document Storage Gateway provides functionality to connect the NoSQL database with other Workday systems. It provides tenant-level encryption and links the documents to the business data so that documents are handled appropriately during tenant management operations.
Big data files uploaded by our customers are stored in HDFS. The assumption here is that the data loaded by customers will be so large that it needs to be processed where it’s stored, as opposed to being moved to where the compute resources are. HDFS and Spark provide the capabilities necessary to process the data in this way.
A number of other persistence solutions are used for specific purposes across the Workday architecture. The diagram above highlights some of them:
Performance Statistics are stored in HDFS. Note that this is a different installation of HDFS to our Big Data Store which is also based on HDFS.
Diagnostic log files are stored in Elasticsearch.
The Search service uses Elasticsearch to support global search and searching within prompts.
The Integration Supervisor manages the queue of integrations in a MySQL database
Worksheets stores some user-created spreadsheets in a MySQL database.
The UI Services access the Shared Sessions data in a Redis in-memory cache. The OMS services also use a Redis cache to manage user sessions and to coordinate some activity at a tenant level.
The Media Content for products such as Workday Learning is stored in Amazon S3.
All of these persistence solutions also conform to Workday’s policies and procedures relating to the backup, recovery, and encryption of tenant data at rest.
Analytics
Workday Prism Analytics provides Workday’s analytics capabilities and manages users’ access to the Big Data Store.
Click play to view a typical Analytics scenario. Users load data into the Big Data Store using the retrieval service. This data is enhanced with data from the transaction service. A regular flow of data from the Transaction Server keeps the Big Data Store up to date.
Users explore the contents of the Big Data Store through the Workday UI and can create lenses that encapsulate how they’d like this data presented to other users. Once a lens is created, it can be used as a report data source just like any other data within the Transaction Server. At run-time the lens is converted into a Spark SQL query which is run against the data stored on HDFS.
Deploying Workday
Workday provides sophisticated tools to support new customers’ deployments. During the deployment phase, a customer’s data is extracted from their legacy system and loaded into Workday. A small team of deployment partners works with the customer to select the appropriate Workday configuration and load the data.
Workday’s multi-tenant architecture enables a unique approach to deployment. All deployment activity is coordinated by the Customer Central application, which is hosted by the OMS. Deployment partners get access to a range of deployment tools through Customer Central. Customers manage partner access using Customer Central

Service Discovery based on ZooKeeper, which allows services to publish their endpoints and to discover other services
Key Management System to support encryption of traffic and data at rest.
The Tenant Supervisor which aggregates the health information from services and reports availability metrics on a per-tenant basis.
Conclusion
Workday’s architecture has changed significantly over the years, yet it remains consistent with the original principles that have made it so successful. Those principles have allowed us to continuously refresh the existing services and adopt new technologies, delivering new functionality to our customers without negatively impacting the applications running on them or the other services around them. We have improved and hardened the abstraction layers as we introduce new functionality and move existing functionality to new services. As a result, Workday reflects both our original architectural choices and the best technologies available today.
At one point in Workday’s history, there were just four services: User Interface (UI), Integration, OMS, and Persistence. Although the Workday architecture today is much more complex, we still use the original diagram below to provide a high-level overview of our services.
At the heart of the architecture are the Object Management Services (OMS), a cluster of services that act as an in-memory database and host the business logic for all Workday applications. The OMS cluster is implemented in Java and runs as a servlet within Apache Tomcat. The OMS also provides the runtime for XpressO — Workday’s application programming language in which most of our business logic is implemented. Reporting and analytics capabilities in Workday are provided by the Analytics service which works closely with the OMS, giving it direct access to Workday’s business objects.
The Persistence Services include a SQL database for business objects and a NoSQL database for documents. The OMS loads all business objects into memory as it starts up. Once the OMS is up and running, it doesn’t rely on the SQL database for read operations. The OMS does, of course, update the database as business objects are modified. Using just a few tables, the OMS treats the SQL database as a key-value store rather than a relational database. Although the SQL database plays a limited role at runtime, it performs an essential role in the backup and recovery of data.
The UI Services support a wide variety of mobile and browser-based clients. Workday’s UI is rendered using HTML and a library of JavaScript widgets. The UI Services are implemented in Java and Spring.
The Integration Services provide a way to synchronize the data stored within Workday with the many different systems used by our customers. These services run integrations developed by our partners and customers in a secure, isolated, and supervised environment. Many pre-built connectors are provided alongside a variety of data transformation technologies and transports for building custom integrations. The most popular technologies for custom integrations are XSLT for data transformation and SFTP for data delivery.
The Deployment tools support new customers as they migrate from their legacy systems into Workday. These tools are also used when existing customers adopt additional Workday products.
Workday’s Operations teams monitor the health and performance of these services using a variety of tools. Realtime health information is collected by Prometheus and Sensu and displayed on Wavefront dashboards as time series graphs. Event logs are collected using a Kafka message bus and stored on the Hadoop Distributed File System, commonly referred to as HDFS. Long-term performance trends can be analyzed using the data in HDFS.
As we’ve grown, Workday has scaled out its services to support larger customers, and to add new features. The original few services have evolved into multiple discrete services, each one focused on a specific task. You can get a deeper understanding of Workday’s architecture by viewing a diagram that includes these additional services. Click play on the video above to see the high-level architecture diagram gain detail as it transforms into a diagram that resembles the map of a city. (The videos in this post contain no audio.)
know more on workday at Workday HCM Online Training
This more detailed architecture diagram shows multiple services grouped together into districts:
These services are connected by a variety of different pathways. A depiction of these connections resembles a city map rather than a traditional software architecture diagram. As with any other city, there are districts with distinct characteristics. We can trace the roots of each district back to the services in our original high-level architecture diagram.
There are a number of landmark services that long-time inhabitants of Workday are familiar with. Staying with the city metaphor, users approaching through Workday Way arrive at the UI services before having their requests handled by the Transaction Services. Programmatic access to the Transaction Service is provided by the API Gateway. The familiar Business Data Store is clearly visible, alongside a relatively new landmark: the Big Data Store where customers can upload large volumes of data for analysis. The Big Data Store is based on HDFS. Workday’s Operations team monitors the health and performance of the city using the monitoring Console based on Wavefront.
User Interface Services
Zooming in on the User Interface district allows us to see the many services that support Workday’s UI.
The original UI service that handles all user generated requests is still in place. Alongside it, the Presentation Services provide a way for customers and partners to extend Workday’s UI. Workday Learning was our first service to make extensive use of video content. These large media files are hosted on a content delivery network that provides efficient access for our users around the globe. Worksheets and Workday Prism Analytics also introduced new ways of interacting with the Workday UI. Clients using these features interact with those services directly. These UI services collaborate through the Shared Session service which is based on Redis. This provides a seamless experience as users move between services.
Metadata-Driven Development
This architecture also illustrates the value of using metadata-driven development to build enterprise applications.
Application developers design and implement Workday’s applications using XpressO, which runs in the Transaction Service. The Transaction Service responds to requests by providing both data and metadata. The UI Services use the metadata to select the appropriate layout for the client device. JavaScript-based widgets are used to display certain types of data and provide a rich user experience. This separation of concerns isolates XpressO developers from UI considerations. It also means that our JavaScript and UI service developers can focus on building the front-end components. This approach has enabled Workday to radically change its UI over the years while delivering a consistent user experience across all our applications without having to rewrite application logic.
The Object Management Services
The Object Management Services started life as a single service which we now refer to as the Transaction Service. Over the years the OMS has expanded to become a collection of services that manage a customer’s data. A brief history lesson outlining why we introduced each service will help you to understand their purpose. Click play on the video below to see each service added to the architecture.
Originally, there was just the Transaction Service and a SQL database in which both business data and documents were stored. As the volume of documents increased, we introduced a dedicated Document Store based on NoSQL.
Larger customers brought many more users and the load on the Transaction Service increased. We introduced Reporting Services to handle read-only transactions as a way of spreading the load. These services also act as in-memory databases and load all data on startup. We introduced a Cache to support efficient access to the data for both the Transaction Service and Reporting Services. Further efficiencies were achieved by moving indexing and search functionality out of the Transaction Service and into the Cache. The Reporting Services were then enhanced to support additional tasks such as payroll calculations and tasks run on the job framework.
Search is an important aspect of user interaction with Workday. The global search box is the most prominent search feature and provides access to indexes across all customer data. Prompts also provide search capabilities to support data entry. Some prompts provide quick access across hundreds of thousands of values. Use cases such as recruiting present new challenges as a search may match a large number of candidates. In this scenario, sorting the results by relevance is just as important as finding the results.
A new search service based on Elasticsearch was introduced to scale out the service and address these new use cases. This new service replaces the Apache Lucene based search engine that was co-located with the Cache. A machine learning algorithm that we call the Query Intent Analyzer builds models based on an individual customer’s data to improve both the matching and ordering of results by relevance.
Scaling out the Object Management Services is an ongoing task as we take on more and larger customers. For example, more of the Transaction Service load is being distributed across other services. Update tasks are now supported by the Reporting Services, with the Transaction Service coordinating activity. We are currently building out a fabric based on Apache Ignite which will sit alongside the Cache. During 2018 we will move the index functionality from the Cache onto the Fabric. Eventually, the Cache will be replaced by equivalent functionality running on the Fabric.
Integration Services
Integrations are managed by Workday and deeply embedded into our architecture. Integrations access the Transaction Service and Reporting Services through the API Gateway.
Persistence
There are three main persistence solutions used within Workday. Each solution provides features specific to the kind of data it stores and the way that data is processed.
Business data is stored in a SQL database which supports tenant management operations such as backup, disaster recovery, copying of tenants, and point-in-time recovery of data.
Documents are stored in a NoSQL database, which provides a distributed document store and disaster recovery. The Document Storage Gateway provides functionality to connect the NoSQL database with other Workday systems. It provides tenant-level encryption and links the documents to the business data so that documents are handled appropriately during tenant management operations.
Big data files uploaded by our customers are stored in HDFS. The assumption here is that the data loaded by customers will be so large that it needs to be processed where it’s stored, as opposed to being moved to where the compute resources are. HDFS and Spark provide the capabilities necessary to process the data in this way.
A number of other persistence solutions are used for specific purposes across the Workday architecture. The diagram above highlights some of them:
Performance Statistics are stored in HDFS. Note that this is a different installation of HDFS to our Big Data Store which is also based on HDFS.
Diagnostic log files are stored in Elasticsearch.
The Search service uses Elasticsearch to support global search and searching within prompts.
The Integration Supervisor manages the queue of integrations in a MySQL database
Worksheets stores some user-created spreadsheets in a MySQL database.
The UI Services access the Shared Sessions data in a Redis in-memory cache. The OMS services also use a Redis cache to manage user sessions and to coordinate some activity at a tenant level.
The Media Content for products such as Workday Learning is stored in Amazon S3.
All of these persistence solutions also conform to Workday’s policies and procedures relating to the backup, recovery, and encryption of tenant data at rest.
Analytics
Workday Prism Analytics provides Workday’s analytics capabilities and manages users’ access to the Big Data Store.
Click play to view a typical Analytics scenario. Users load data into the Big Data Store using the retrieval service. This data is enhanced with data from the transaction service. A regular flow of data from the Transaction Server keeps the Big Data Store up to date.
Users explore the contents of the Big Data Store through the Workday UI and can create lenses that encapsulate how they’d like this data presented to other users. Once a lens is created, it can be used as a report data source just like any other data within the Transaction Server. At run-time the lens is converted into a Spark SQL query which is run against the data stored on HDFS.
Deploying Workday
Workday provides sophisticated tools to support new customers’ deployments. During the deployment phase, a customer’s data is extracted from their legacy system and loaded into Workday. A small team of deployment partners works with the customer to select the appropriate Workday configuration and load the data.
Workday’s multi-tenant architecture enables a unique approach to deployment. All deployment activity is coordinated by the Customer Central application, which is hosted by the OMS. Deployment partners get access to a range of deployment tools through Customer Central. Customers manage partner access using Customer Central
Deployment starts with the creation of a foundation tenant. Working in conjunction with the customer, deployment partners select from a catalog of pre-packaged configurations based on which products they are deploying. Pre-packaged configurations are also available for a range of different regulatory environments.
The next step is to load the customer’s data into the Big Data Store. The data is provided in tabular form and consultants use CloudLoader to transform, cleanse and validate it before loading it into the customers’ tenant.
Customer Central supports an iterative approach to deployment. Multiple tenants can easily be created and discarded as the data loading process is refined and different configuration options are evaluated. The Object Transporter service provides a convenient way to migrate configuration information between tenants. These tenants provide the full range of Workday features. Customers typically use this time to evaluate business processes and reporting features. Customers may also run integrations in parallel with their existing systems in preparation for the switch over.
As the go-live date approaches, one tenant is selected as the production tenant to which the customers’ employees are granted access. Customers may continue to use Customer Central to manage deployment projects for additional Workday products or to support a phased roll-out of Workday.
The primary purpose of these tools is to optimize the deployment life cycle. Initially, the focus is on the consulting ecosystem. As these tools reach maturity, customers gain more access to these features and functionality. In time, these tools will allow customers to become more self-sufficient in activities such as adopting new products, or managing mergers and acquisitions.
Operations
Workday’s Operations team monitors services using the Wavefront monitoring console. The team also receives alerts through Big Panda. Health metrics are emitted by each service using either Prometheus or Sensu and sent over a RabbitMQ message bus to the metric processing backend. This backend then feeds the metrics to the monitoring console and the alerts to the alerting framework.

Diagnostic Logs are collected through a Kafka message bus and stored in Elasticsearch where they can be queried using Kibana. Performance Statistics are also collected by Kafka. They are stored in Hadoop where they can be queried using Hive, Zeppelin, and a number of other data analytic tools.
The next step is to load the customer’s data into the Big Data Store. The data is provided in tabular form and consultants use CloudLoader to transform, cleanse and validate it before loading it into the customers’ tenant.
Customer Central supports an iterative approach to deployment. Multiple tenants can easily be created and discarded as the data loading process is refined and different configuration options are evaluated. The Object Transporter service provides a convenient way to migrate configuration information between tenants. These tenants provide the full range of Workday features. Customers typically use this time to evaluate business processes and reporting features. Customers may also run integrations in parallel with their existing systems in preparation for the switch over.
As the go-live date approaches, one tenant is selected as the production tenant to which the customers’ employees are granted access. Customers may continue to use Customer Central to manage deployment projects for additional Workday products or to support a phased roll-out of Workday.
The primary purpose of these tools is to optimize the deployment life cycle. Initially, the focus is on the consulting ecosystem. As these tools reach maturity, customers gain more access to these features and functionality. In time, these tools will allow customers to become more self-sufficient in activities such as adopting new products, or managing mergers and acquisitions.
Operations
Workday’s Operations team monitors services using the Wavefront monitoring console. The team also receives alerts through Big Panda. Health metrics are emitted by each service using either Prometheus or Sensu and sent over a RabbitMQ message bus to the metric processing backend. This backend then feeds the metrics to the monitoring console and the alerts to the alerting framework.

Diagnostic Logs are collected through a Kafka message bus and stored in Elasticsearch where they can be queried using Kibana. Performance Statistics are also collected by Kafka. They are stored in Hadoop where they can be queried using Hive, Zeppelin, and a number of other data analytic tools.

The Operations district includes a number of automated systems that support Workday’s services. These include:
Workday-specific Configuration management systemsService Discovery based on ZooKeeper, which allows services to publish their endpoints and to discover other services
Key Management System to support encryption of traffic and data at rest.
The Tenant Supervisor which aggregates the health information from services and reports availability metrics on a per-tenant basis.
Conclusion
Workday’s architecture has changed significantly over the years, yet it remains consistent with the original principles that have made it so successful. Those principles have allowed us to continuously refresh the existing services and adopt new technologies, delivering new functionality to our customers without negatively impacting the applications running on them or the other services around them. We have improved and hardened the abstraction layers as we introduce new functionality and move existing functionality to new services. As a result, Workday reflects both our original architectural choices and the best technologies available today.



0 comments:
Post a Comment